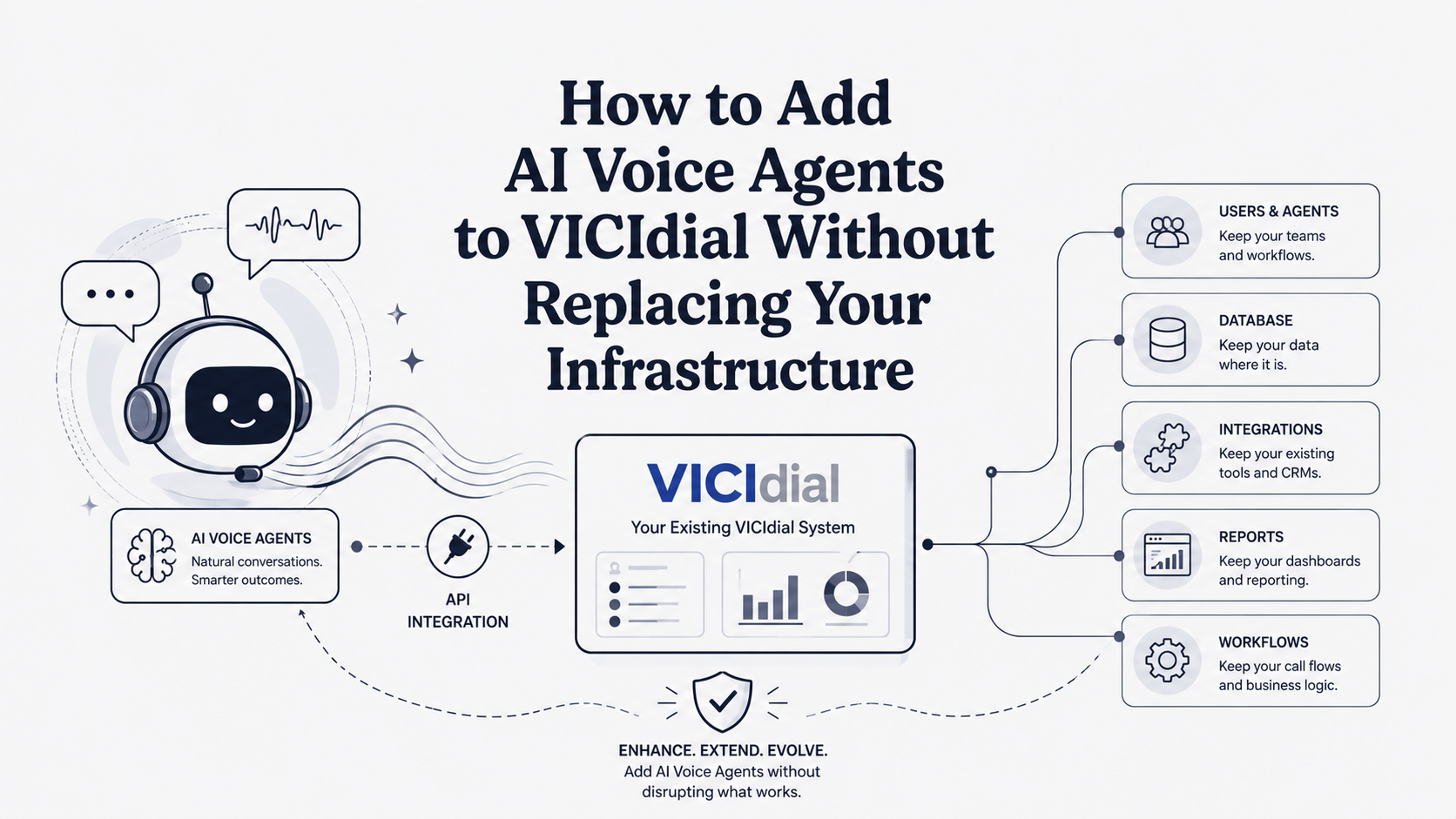
Best Voice AI API (2026): 11 Production-Ready Options
Discover the Best Voice AI API in 2026: 11 platforms compared on per-minute cost, latency, telephony reach, and warm transfers. See the picks.
May 19, 2026
TL;DR
Choosing the best voice AI API in 2026 comes down to four things: total per-minute cost (not headline price), latency consistency under real call volumes, telephony reach, and how well the platform handles warm transfers to humans. This guide breaks down 11 production-ready voice AI APIs across pricing, features, and honest tradeoffs. SigmaMind AI stands out for developer-first orchestration with model-agnostic flexibility, while alternatives like Retell and LiveKit serve different needs depending on team size and technical depth.
What “Best” Actually Means for Production Voice AI
Picking the best voice AI API is not a demo problem. It is a production problem. The difference between a voice agent that impresses in a five-minute test and one that handles thousands of concurrent calls without awkward pauses, billing surprises, or dropped transfers is enormous.
Developers and agency builders searching for the best voice AI APIs care about specifics: What does a minute actually cost after you stack up platform fees, STT, TTS, LLM inference, and telephony? How consistent is latency at the 95th percentile, not just the median? Can you buy phone numbers in the countries you need, or are you stuck importing SIP trunks?
Practitioners on Reddit’s r/AIVoice_Agents have been blunt about this. As one builder put it, “I don’t trust $0.10/min anymore. If I can’t model cost per qualified conversation, it’s not real pricing.” That skepticism is warranted. Most comparison articles skim these details or push vendor talking points. This one doesn’t.
Quick Decision Framework
Before comparing all 11 voice AI APIs, narrow the field with four questions.
Step 1: Pick Your Architecture
Managed voice-agent platforms get you to production fastest. You configure agents, connect telephony, and ship. Examples: SigmaMind AI, Retell, Bland, Voiceflow, Cognigy, PolyAI.
API and foundation layers give you more control but more operational work. You assemble STT, LLM, TTS, and telephony yourself. Examples: LiveKit Agents, OpenAI Realtime API, Deepgram, Hume AI.
Step 2: Model True Cost Per Minute
A “flat” per-minute price from a managed platform is not always flat. And a “cheap” DIY stack is not always predictable. Measure cost per resolved conversation, not headline dollars per minute. Watch for excluded layers, add-on fees for transfers or SMS, and minimum call-attempt charges.
Step 3: Confirm Production Must-Haves
Target sub-second voice-to-voice response times. Prioritize latency consistency over best-case numbers, because callers feel jitter more than they notice a slightly slower but steady pace. Confirm barge-in (interruptibility) works cleanly. Verify warm transfer with context so human agents receive a summary instead of forcing the caller to repeat everything.
Step 4: Face Telephony Reality
US local outbound costs roughly $0.013 to $0.015 per minute through Twilio. Telnyx can be lower with volume commitments. But international rates run 10 to 20 times higher in some regions, and many voice AI platforms only provision US numbers natively. If you need local presence in Europe, LATAM, or APAC, expect to bring your own SIP trunks.
At-a-Glance Comparison Table
| Platform | Starting Price | What’s Included | Best For | Telephony | Key Tradeoff |
|---|---|---|---|---|---|
| SigmaMind AI | $0.03/min platform + provider costs | Orchestration, analytics, warm transfer | Developer-led production agents | US numbers + BYO SIP | Global numbers require BYO carrier |
| Retell AI | $0.07–$0.31/min | Voice infra, TTS, LLM (varies by config) | Fast time-to-ship for small teams | Via Twilio/Telnyx routing | Final cost depends on model/TTS choices |
| Vapi | $0.05/min platform + pass-through | Orchestration layer only | Low-level API control | BYO telephony | Total often $0.15–$0.40/min |
| Bland AI | $0.11–$0.14/min | LLM, STT, TTS, telephony (claimed) | One-invoice simplicity | Built-in | Watch add-on fees closely |
| Voiceflow | Usage-based (in-app) | Visual builder, multichannel | No-code design teams | US/CA + BYO carrier | Less public pricing transparency |
| Cognigy | Enterprise custom | Voice Gateway, CCaaS integrations | Large enterprise contact centers | Via Voice Gateway | Heavy implementation, complex pricing |
| PolyAI | Enterprise custom (~£0.15–0.27/min at scale) | Fully managed voice agents | High-touch contact center automation | Managed | Limited developer API freedom |
| LiveKit Agents | Open-source + Cloud pricing | Media SFU, agent SDK | Engineers building custom stacks | BYO SIP (Twilio/Telnyx) | You own the entire ops burden |
| OpenAI Realtime API | Per-second model billing | Full-duplex audio, function calling | Cutting-edge model capabilities | None (BYO everything) | No telephony, STT/TTS, or orchestration |
| Deepgram | Per-minute STT/TTS | Streaming STT, Aura TTS | Speech layer for DIY pipelines | None | No orchestration or agent logic |
| Hume AI (EVI 3) | Subscription + usage | Empathic Voice Interface, expressive TTS | Tone-sensitive use cases | None | Smaller ecosystem, niche positioning |
The 11 Best Voice AI APIs in 2026
1. SigmaMind AI

Best for: Developer-led teams needing model-agnostic orchestration, warm transfers, and per-layer analytics across voice, chat, and email.
Pricing:
- Platform fee: $0.03/min for voice agents, plus pass-through costs for STT, TTS, LLM, and telephony at provider rates
- Chat agents: $0.005 per AI message platform fee plus LLM and optional SMS at cost
- Enterprise volume pricing available
- See the SigmaMind pricing calculator
Key features:
- No-code agent builder with node-based, stateful workflows, plus deep APIs and an MCP server for IDE-level orchestration
- Model-agnostic: supports Deepgram (STT), ElevenLabs, Rime AI, and Cartesia (TTS), plus OpenAI, Claude, Gemini, and Hume (LLM)
- Built-in US number purchase and BYO carrier via SIP (Twilio/Telnyx)
- Warm transfer with structured context headers, so human agents get AI summaries and machine-readable data before the caller connects
- Outbound campaigns with CSV upload, scheduling, and concurrency controls
- Per-layer analytics breaking down cost, duration, transfers, and tool calls
- Omnichannel: same agent logic across voice, chat, and email
- Multi-workspace management for agencies handling multiple client accounts
- App library with CRM, helpdesk, e-commerce, and calendar integrations
Tradeoffs:
- Direct number purchase limited to US; international deployments need BYO Twilio or Telnyx SIP configuration
- Modular pricing requires budgeting across providers (though the calculator makes this transparent)
- HIPAA-friendly workflows available, but full HIPAA compliance may require BAAs and private cloud options
- Dependent on third-party AI providers for STT/TTS/LLM, meaning quality can shift with vendor updates
Real-world perspective:
SigmaMind’s case studies show measurable outcomes: 4,000+ refunds per month automated with 43% lower cost, and one D2C brand cut first-response time by 50% within three months. For agencies, the multi-workspace and full-agent-import features eliminate hours of duplicated setup across client accounts.
2. Retell AI

Best for: Small teams that want predictable per-minute pricing and minimal setup time.
Pricing:
- Pay-as-you-go: $0.07 to $0.31/min depending on configuration
- Component breakdown: voice infrastructure $0.055/min, TTS $0.015/min (platform voices), LLM from $0.04/min
- 20 free concurrent calls on pay-as-you-go
- Enterprise custom pricing available
Key features:
- Sub-second latency targets with an agent-level latency estimator in their docs
- Templates and webhooks for quick deployment
- Support for ElevenLabs, Cartesia, OpenAI voices, and multiple LLMs
- Latency estimator helps predict performance based on prompt length, knowledge base lookups, and tool calls
Tradeoffs:
- Final cost varies significantly based on selected LLM and TTS provider
- Telephony management still falls on you (Twilio/Telnyx setup required for global coverage)
- Less orchestration depth compared to platforms with node-based workflow builders
Real-world perspective:
Practitioners on Reddit’s r/AI_Agents consistently praise Retell’s reliability at small scale. One builder noted, “Retell was hardest to beat for small teams at around 3,000 minutes per month because of predictability and time-to-ship.” Multiple users describe it as the platform that “just works” for getting a first agent live fast.
3. Vapi

Best for: Engineering-led teams comfortable modeling total cost and choosing every provider in the stack.
Pricing:
- Platform fee: approximately $0.05/min plus at-cost pass-through billing for STT, LLM, TTS, and telephony
- Real-world totals frequently land between $0.15 and $0.40/min depending on provider choices
- Enterprise volume discounts available
Key features:
- API-first orchestration across multiple providers
- Per-call billing breakdowns showing exactly what each layer cost
- Common stacks include Deepgram + OpenAI + ElevenLabs
- Extensive documentation on cost estimation
Tradeoffs:
- Pricing described as “confusing” and highly variable by multiple community members
- Cost predictability requires careful provider tuning and forecasting
- Compliance add-ons may require negotiation on enterprise plans
Real-world perspective:
Builders on r/AI_Agents praise Vapi’s control but flag the complexity. One agency owner shared that after adding up all provider costs, the total was meaningfully higher than the headline platform fee suggested. Agencies using Vapi often build white-label billing layers to pass costs through to their own clients.
4. Bland AI

Best for: Operations teams that want one invoice and minimal stack assembly.
Pricing:
- Plans range from $0.11 to $0.14/min (Start tier at $0.14/min)
- Claims to include LLM, STT, TTS, and telephony in the per-minute rate
- Concurrency and daily caps vary by tier
- Enterprise custom pricing available
Key features:
- Batch dialing for outbound campaigns
- Warm transfers and knowledge bases
- Voice cloning capabilities
- “Norm” visual builder
- Self-hosted options for enterprise
Tradeoffs:
- “All-inclusive” label deserves scrutiny: transfers, SMS, number rental, and recording may carry additional fees
- Fewer model configuration options compared to orchestration-first platforms
- Verify international coverage and any add-on rates before committing
- Some tiers have minimum call-attempt fees
Real-world perspective:
The appeal of a single per-minute rate is obvious. But community threads on r/AIVoice_Agents urge scrutiny. As one practitioner warned, “Flat rate is compelling until you see the add-ons showing up on your invoice.” Always request a detailed breakdown of what “all-inclusive” actually covers for your specific use case.
5. Voiceflow

Best for: CX and design teams that need to ship voice agents fast without deep coding.
Pricing:
- Plan pricing visible in-app with usage-based billing and credit bundles
- Can provision US and Canadian numbers directly
- Supports Twilio, Vonage, and Telnyx as BYO carriers
Key features:
- Visual conversation builder with drag-and-drop interface
- Multichannel support (voice, chat, web)
- Inbound and outbound phone capabilities
- Transcripts and analytics included
- Enterprise deployment options
Tradeoffs:
- Less public pricing transparency compared to competitors with published rate cards
- Advanced development teams may outgrow no-code constraints
- Telephony options more limited outside US/Canada without BYO carrier setup
Real-world perspective:
Reviewers consistently highlight Voiceflow’s intuitive builder as a strength for non-technical team members. One reviewer noted it’s “great for getting something live quickly, but developers may want more control as complexity grows.” The visual interface is genuinely useful for prototyping conversation flows before committing to a production stack.
6. Cognigy

Best for: Large enterprises standardizing on CCaaS with agentic AI across voice and digital channels.
Pricing:
- Custom enterprise pricing (not publicly listed)
- Positioned for enterprise-scale orchestration
- NICE announced acquisition of Cognigy in 2025, aligning with CCaaS infrastructure
Key features:
- Voice Gateway for SIP-based telephony integration
- Agent assist capabilities alongside full automation
- Integrations across major CCaaS platforms
- Enterprise RBAC, SLAs, and frequent release cycles
Tradeoffs:
- Heavy implementation with steep learning curve
- Pricing and billing complexity typical of enterprise software
- Not suited for API-minimalist teams or startups
- Peer reviews on Gartner highlight power alongside rollout complexity
Real-world perspective:
Cognigy is the choice when voice AI sits inside a larger enterprise contact center transformation. Gartner peer reviewers acknowledge its capability but consistently mention the time investment required for deployment. This is not a weekend project.
7. PolyAI

Best for: Contact centers that want fully managed, high-touch voice automation without building anything themselves.
Pricing:
- Enterprise custom pricing
- Public procurement data (UK G-Cloud 14) lists volume per-minute ranges from approximately £0.27 down to £0.15 at 8M+ annual minutes
- Forrester TEI study documents ROI drivers for enterprise deployments
Key features:
- Fully managed voice agent design, build, and operation
- Multilingual support
- Enterprise-grade delivery with dedicated teams
- Strong case studies in high-stakes environments (hospitality, financial services)
Tradeoffs:
- Custom pricing means no self-serve experimentation
- Limited developer-led API freedom; this is a managed service, not a building block
- Smaller teams or budget-conscious startups are not the target market
Real-world perspective:
G2 reviews praise PolyAI’s enterprise-grade reliability and the quality of managed delivery. The trade is control: you are buying outcomes, not API keys. For large contact centers with budget and patience for vendor onboarding, PolyAI delivers.
8. LiveKit Agents

Best for: Senior engineers who want full portability, open-source flexibility, and the option to run on-premises.
Pricing:
- Open-source framework (self-host for free)
- LiveKit Cloud offers per-minute agent and session pricing
- Telnyx partnership emphasizes carrier-native deployments
- BYO SIP via Twilio or Telnyx for telephony
Key features:
- Real-time media SFU (Selective Forwarding Unit) for low-latency audio routing
- Agent SDK with telephony field guides covering transfers, UUI headers, and caller ID
- Run on cloud, on-premises, or private infrastructure
- Integrates with any STT, LLM, and TTS provider
Tradeoffs:
- You assemble and manage the entire stack (STT, LLM, TTS, telephony)
- Production telephony involves SIP configuration quirks that take time to resolve
- Observability and analytics are your responsibility
- Operational overhead is significantly higher than managed platforms
Real-world perspective:
Builders on r/AI_Agents and r/livekit report that LiveKit with SIP is powerful but demands production tuning. One developer shared, “Production telephony had surprises. Docs helped, but expect time tuning transfers and filler phrases.” Another flagged SIP trunk stability issues that required workarounds. If you have the engineering bandwidth, the control is unmatched.
9. OpenAI Realtime API

Best for: Teams building custom voice pipelines who want the most capable conversational model as their foundation.
Pricing:
- Billed per second for realtime models
- SKUs include gpt-realtime-mini and higher tiers
- Token caching discounts for text and audio reduce costs in some patterns
- Full pricing details on OpenAI’s platform docs
Key features:
- Full-duplex audio (true simultaneous speaking and listening)
- Native function and tool calling within the conversation
- Multimodal capabilities
- Pairs well with LiveKit or Telnyx for telephony layer
Tradeoffs:
- No built-in telephony, STT, TTS orchestration, or agent management
- You need to bring everything else: SIP provider, audio routing, conversation state, analytics
- Requires rigorous latency budgeting since model inference is only one piece of total mouth-to-ear time
- Costs can be unpredictable with long conversations or heavy tool use
Real-world perspective:
One builder on r/aiagents described shipping an entire call agent platform in two days using SIP connected to the Realtime API with tool calling. Their assessment: “Conversational quality felt human.” The speed of prototyping is impressive, but production hardening (error handling, fallbacks, cost controls) takes considerably longer.
10. Deepgram
Best for: Teams composing their own voice stack who need reliable, low-latency STT and TTS as building blocks.
Pricing:
- Transparent per-minute pricing for STT and TTS (Aura)
- Concurrency limits by plan tier
- Pay-as-you-go and annual credit options
- Full rate card published publicly
Key features:
- Streaming speech-to-text with strong accuracy across accents
- Aura TTS for low-latency voice synthesis
- Contact center guidance and scale-oriented documentation
- Common default STT provider in Vapi and LiveKit pipelines
Tradeoffs:
- No orchestration, agent logic, telephony, or conversation management
- You must pair with LLM, TTS (if not using Aura), and telephony providers separately
- Voice persona and conversation design happen elsewhere
- Value depends entirely on what you build around it
Real-world perspective:
Deepgram is the go-to STT for many voice AI builders. Agencies frequently cite it as “good enough and cheap” for real-time transcription. It appears as a default provider in multiple orchestration platforms, which speaks to its reliability as a pipeline component.
11. Hume AI (EVI 3)

Best for: Use cases where emotional tone and prosody directly affect outcomes, such as healthcare, hospitality, or mental health support.
Pricing:
- Subscription plus usage-based billing
- EVI and TTS included in platform pricing
- Billing documentation available in their developer docs
Key features:
- Empathic Voice Interface (EVI) for real-time speech-to-speech interaction
- Expressive TTS that adjusts tone based on conversation context
- Emotion measurement API for analytics
- Speech-to-speech architecture that can reduce latency by cutting out intermediate text steps
Tradeoffs:
- Smaller ecosystem compared to established STT/TTS providers
- Pricing and fit should be validated through head-to-head pilots at your expected volume
- Less established track record in high-concurrency telephony deployments
- May require combining with other platforms for full agent orchestration
Real-world perspective:
Interest in Hume is growing among builders focused on emotionally nuanced interactions. The speech-to-speech approach is architecturally interesting for latency reduction. But for most standard voice agent use cases (scheduling, support, sales), the empathic features add cost and complexity that may not move the needle on outcomes.
How to Estimate Total Voice AI Cost (Two Worked Examples)
The biggest mistake when evaluating voice AI APIs is trusting headline pricing. Here is what a single minute actually costs under two common architectures.
Example 1: DIY Layered Stack (Vapi-style)
| Layer | Cost per Minute |
|---|---|
| Platform fee (Vapi) | $0.05 |
| STT (Deepgram) | ~$0.01 |
| LLM (OpenAI GPT-4o) | ~$0.04–0.08 |
| TTS (ElevenLabs) | ~$0.03–0.06 |
| Telephony (Twilio US outbound) | ~$0.014 |
| Total | $0.14–$0.21 |
Real-world totals often reach $0.15 to $0.40/min depending on model choice and call complexity. Tool calls and long prompts push LLM costs higher.
Example 2: Managed Platform (SigmaMind AI)
| Layer | Cost per Minute |
|---|---|
| Platform fee | $0.03 |
| STT (Deepgram, at cost) | ~$0.01 |
| LLM (model of choice, at cost) | ~$0.04–0.08 |
| TTS (ElevenLabs/Rime/Cartesia, at cost) | ~$0.02–0.06 |
| Telephony (Twilio/Telnyx, at cost) | ~$0.014 |
| Total | $0.11–$0.19 |
The lower platform fee creates room. But the real advantage is per-layer cost breakdowns that let you swap providers when pricing or quality shifts.
What to Actually Measure
Stop optimizing for raw cost per minute. Practitioners on r/AIVoice_Agents consistently argue that cost per qualified conversation or cost per resolved intent is the metric that matters. A $0.20/min agent that resolves issues in 90 seconds beats a $0.10/min agent that takes four minutes and still transfers to a human.
Latency Tuning Checklist
Latency consistency matters more than occasional fast responses. As one builder on Reddit explained, “Latency jitter is what users notice. Staying steady beats one-off 300 ms spikes.” Here is what to check.
Prompt size: Longer system prompts increase LLM inference time. Keep prompts concise and move reference material into structured knowledge bases that load on demand.
Knowledge base lookups: Every retrieval step adds a network round trip. Index tightly and cache aggressively.
Tool calls: Function calls that hit external APIs (CRM lookups, calendar checks) add unpredictable latency. Use timeouts and fallback responses.
Barge-in settings: The agent needs to stop speaking immediately when the caller interrupts. Poor barge-in handling creates the uncanny “talking over each other” effect that makes callers hang up.
Architecture: Most production stacks use cascaded streaming (STT to LLM to TTS) with pipelining at each stage. Minimizing network hops between components is the single biggest latency lever. Research on real-time voice pipelines confirms that careful pipelining outweighs model speed improvements.
Test under load: p50 latency is vanity. p95 and p99 under concurrent call volumes reveal the real experience. Use the SigmaMind playground or equivalent tools to test before going live.
Handoffs That Don’t Break the Customer Experience
The moment a voice AI agent transfers a call to a human is the moment most CX gains evaporate. If the human agent asks “Can you tell me what you were calling about?”, every dollar spent on AI was partially wasted.
Warm transfer with structured context solves this. The AI passes a summary of the conversation, extracted intent, customer variables (order number, account ID), and any actions already taken. The human agent sees this before they even greet the caller.
Agencies building customer support voice agents rank warm transfer quality as their top selection criterion. They sell outcomes to their clients, and a botched handoff destroys the metrics they are measured on.
What to look for in a voice AI API’s transfer capabilities:
- Structured headers: Can the platform pass custom SIP headers or webhook payloads with conversation data?
- Context whispering: Does the human agent hear or see a brief summary before the caller is connected?
- Partial resolution tracking: If the AI completed two of three steps, does the human know which step remains?
- CRM integration: Are conversation details written to the CRM before transfer, so the human has full context in their existing interface?
SigmaMind AI, Bland, and LiveKit all support warm transfers, but the depth of structured context varies. SigmaMind’s approach includes context headers and human whisper functionality that passes machine-readable data alongside natural language summaries.
Telephony Gotchas by Region
US deployments are straightforward. Most voice AI APIs either provision US numbers directly or integrate with Twilio and Telnyx, where outbound local rates run about $0.013 to $0.015 per minute. Volume discounts apply.
Outside the US, things get complicated fast.
International rates: Outbound to mobile numbers in many countries costs 10 to 20 times the US rate. A voice agent calling UK mobiles, Brazilian numbers, or Indian lines will see telephony become the dominant cost layer.
Number availability: Most platforms offering “built-in telephony” mean US numbers. For local presence in Europe, LATAM, or APAC, you typically need BYO SIP trunks through Twilio, Telnyx, or regional carriers.
Regulatory requirements: Some countries require local entity registration to purchase phone numbers. Others restrict automated outbound calling. These are not API problems; they are legal and operational problems that no voice AI platform fully abstracts away.
Billing increments: Check whether your telephony provider bills in 1-second, 6-second, or 60-second increments. On short calls (IVR navigation, quick confirmations), 60-second minimums inflate costs dramatically.
For teams deploying globally, the practical path is to choose a voice AI API that supports BYO SIP, then negotiate carrier rates separately for each region. SigmaMind AI, LiveKit, Vapi, and Voiceflow all support this approach.
How to Choose Fast
Need production voice agents now with predictable billing? Start with Retell (small teams) or Bland (one-invoice simplicity).
Need model freedom, multi-workspace agency operations, warm transfer with context, and per-layer analytics? SigmaMind AI is built for this. Start free and pay only for what you use.
Need full control, on-premises options, or a custom pipeline? Compose with LiveKit Agents + OpenAI Realtime + Deepgram or Hume + BYO SIP.
Enterprise contact center with existing CCaaS? Evaluate Cognigy or PolyAI, but budget for longer implementation timelines.
For teams that want to test before committing, SigmaMind offers a free tier with usage-based billing. Build your first agent or talk to the team about enterprise requirements.
FAQ
What is a voice AI API?
A voice AI API is a programming interface that lets developers build applications where AI agents conduct real-time voice conversations. These APIs typically handle some combination of speech-to-text, language model inference, text-to-speech, and telephony integration, either as bundled services or composable layers.
How much does a voice AI API cost per minute?
Total costs range from about $0.11/min on the low end (managed platform with efficient provider choices) to $0.40/min or more for premium LLM and TTS configurations. The headline platform fee is never the full picture. Always account for STT, LLM, TTS, and telephony costs separately, then benchmark against cost per resolved conversation rather than raw per-minute rate.
Which voice AI API has the lowest latency?
Latency depends on the entire pipeline, not just one vendor. Most production voice AI systems target sub-second voice-to-voice response times using cascaded streaming (STT to LLM to TTS). SigmaMind AI targets sub-second latency, and Retell’s documentation references approximately 600 ms silence-to-first-token in optimal configurations. The key metric is consistency at the 95th percentile under real call volumes, not best-case demos.
Can I use my own phone numbers with these APIs?
Yes, most voice AI APIs support BYO SIP (Session Initiation Protocol) trunking through providers like Twilio or Telnyx. Some platforms also let you purchase US numbers directly. For international numbers, BYO SIP is almost always required.
Which voice AI API is best for agencies managing multiple clients?
SigmaMind AI is purpose-built for this with multi-workspace management, full agent import (clone entire agent configurations across client accounts), and per-layer analytics that help agencies track costs per client. Vapi and Retell can also work for agencies, but require more custom tooling for multi-client operations.
Do any voice AI APIs support HIPAA compliance?
Several platforms offer HIPAA-friendly workflows, but full HIPAA compliance typically requires Business Associate Agreements (BAAs), encryption controls, and sometimes private cloud deployment. SigmaMind AI supports HIPAA-friendly workflows and offers private cloud options for healthcare use cases, though organizations should verify compliance requirements directly with any vendor before handling protected health information.
What is the difference between managed and DIY voice AI stacks?
Managed platforms (SigmaMind, Retell, Bland) bundle orchestration, and sometimes telephony, into a single product. You configure and ship without assembling individual components. DIY stacks (LiveKit + Deepgram + OpenAI + SIP provider) give maximum control and portability but require engineering effort for integration, observability, error handling, and scaling. The right choice depends on your team’s engineering capacity and how much operational overhead you can absorb.
How do I test a voice AI API before committing?
Most platforms offer free tiers or trial credits. SigmaMind AI lets you start building for free with pay-as-you-go billing. Retell provides 20 free concurrent calls on their starter plan. For DIY stacks, LiveKit’s open-source framework can be self-hosted at no platform cost. Run pilots with real call scenarios (not just scripted demos) and measure latency consistency, transfer quality, and total cost per conversation before scaling.