AI Voice Agent Testing Platform: 11 Best (2026 Guide)
Compare 11 tools with realistic call simulation, audio metrics, PSTN validation, and CI/CD gating. Pick the right AI Voice Agent Testing Platform.
May 19, 2026
TL;DR
Testing AI voice agents requires far more than chatbot-style transcript checks. The best AI voice agent testing platforms in 2026 combine realistic call simulation (accents, interruptions, background noise), audio-native evaluations, PSTN validation, load testing with real concurrency, and CI/CD gating on voice-specific KPIs. This guide covers 11 platforms, from full-stack orchestration tools like SigmaMind AI to specialized testing suites like Hamming and Cekura, with honest pricing notes, tradeoffs, and practitioner feedback from Reddit and builder communities.
Why Voice Agent Testing Is Not Chatbot Testing
A chatbot that returns the wrong answer is annoying. A voice agent that returns the wrong answer 1.8 seconds too late, while talking over the caller, on a choppy PSTN line, is a disaster.
Voice adds three constraint layers that text never deals with: timing (latency, turn-taking, barge-in behavior), audio quality (codec artifacts, background noise, prosody), and telephony infrastructure (PSTN routing, DTMF tones, carrier-specific quirks). Demos built on WebRTC console calls routinely hide these problems. Practitioners on Reddit warn that “AI voice agents in 2026” demos often break the moment they hit real phone lines, where transcoding, jitter, and mobile carrier paths introduce failures that never appeared in development.
This is why a purpose-built AI voice agent testing platform matters. Generic API testing or transcript-only evaluations will miss the exact issues that make callers hang up.
At-a-Glance Comparison Table
Pricing data is as of April 26, 2026. Where vendors use “contact sales,” we note the pricing model.
| Platform | Best For | Key Differentiator | Pricing (Public) | CI/CD | Production Replay | Simulation Depth |
|---|---|---|---|---|---|---|
| SigmaMind AI | Build, test, and deploy in one stack | In-builder playground + APIs/MCP for CI | $0.03/min platform + provider costs | Yes (API/MCP) | Via analytics | Deep (multi-channel) |
| Hamming AI | Regulated, high-stakes at scale | Audio-native evals + HIPAA/BAA + 50+ metrics | Contact sales | Yes | Yes | Deep (personas, noise) |
| Cekura | Fast setup, multi-language | Frequency-based load testing; chat-mode tests | Not public (dev plan: 10 concurrent) | Yes | Yes | Deep (30+ languages) |
| Roark | Production analytics + replay loop | 40+ metrics; graph-based scenarios | Consumption + minimum spend | Yes | Yes | Deep |
| Coval | CI regression on every commit | CI pipelines; Slack/Linear alerting | Contact sales | Yes | Yes | Deep |
| Tuner | Observability-first, transparent pricing | Public pricing; fast onboarding | $30/$400/custom per month | Emerging | Strong | Growing |
| Braintrust + Evalion | Unified voice + text evaluation | Audio attachments; custom scorers | Free/$249+/custom | Yes | Yes | Via Evalion pairing |
| VoxTest | YAML-defined CI scenarios | CLI parallelization; low vendor lock-in | Not public | Yes | Light | Yes |
| TestVoice AI | Agencies on Vapi/Retell/Bland | Campaign-style regression runs | Trial/demo | Yes | Yes | Yes |
| voicetest.dev | OSS-first CI testing | GitHub Actions-ready; zero SaaS dependency | Open source | Yes | Minimal | DIY |
| LiveKit Helpers | Unit tests during development | Fast text-mode correctness checks | Free (framework) | Partial | No | Text-only default |
How to Choose: The Decision Framework
Before comparing vendors, define what your voice agent testing stack actually needs to do. Five jobs matter, roughly in the order you’ll hit them:
1. Simulation and scenario coverage. Can it generate realistic callers with accents, interruptions, impatient personas, and background noise? Or are you stuck writing scripts by hand?
2. Audio pipeline and latency validation. Does it measure time-to-first-word (TTFW), barge-in success rate, and talk/listen ratio at the audio level? Does it test on PSTN lines, not just WebRTC? According to Hamming’s testing framework, a natural-feeling TTFW target sits under roughly 2 seconds, with stricter targets for premium customer experiences.
3. Load and failure-mode discovery. Can it shape realistic load (calls per second, sustained concurrency) and expose provider-side caps? Cekura’s load testing docs note that you need minimum call durations to actually maintain concurrency, not just fire-and-forget short bursts.
4. Regression and CI/CD gating. Can you convert production failures into deterministic test cases and block deploys when voice KPIs degrade?
5. Production observability and replay. Does it capture structured traces, 40-50+ metrics, and let you replay failing calls against new agent versions?
North-Star Voice KPIs to Track
These are the metrics that separate shipped-and-forgotten voice agents from continuously improving ones. For a deeper breakdown, see this guide on measuring the quality of AI call interactions:
- TTFW (time to first word): Under ~2 seconds at p95 for natural feel
- Task/goal completion rate: Did the agent actually finish the job?
- Interruption handling success: Can it recover gracefully from barge-in?
- Escalation rate: How often does it need a human?
- Word error rate (WER): Under realistic noise, not lab conditions
- Talk/listen ratio: Agents that monologue lose callers
- Turn-taking latency distribution: Not just averages, the p95 and p99
What “Good” Voice Agent Testing Actually Includes in 2026
Most articles stop at “run some test calls.” Here is what practitioners who ship production voice agents actually do.
Don’t Stop at Transcripts
Transcript-based evaluation misses everything that makes voice feel wrong. Audio-native checks catch barge-in failures, silence gaps, gibberish bursts from STT errors, and sentiment shifts detectable only through prosody. Hamming’s platform, for instance, analyzes 50+ metrics including monologue detection and frustration signals at the audio level. If your testing platform only scores transcripts, you are grading a voice agent like a chatbot.
Validate on Real Phone Lines
This is the gap that burns teams hardest. WebRTC console calls bypass the entire PSTN path: codec transcoding, carrier routing, DTMF handling, and mobile-specific quirks. A product manager on Reddit shared real production anomalies where UK mobile prefixes triggered codec oddities that observability tooling caught but manual testing completely missed. Test on actual phone lines before launch. Every time.
Shape Realistic Load
A common mistake: running 100 simultaneous test calls that each last 5 seconds. That tests nothing. Real concurrency means sustaining calls at production-length durations while ramping calls per second. You also need to know your provider’s concurrency caps. Cekura’s documentation describes frequency-based scheduling at 5 calls per second with developer-plan caps of 10 concurrent calls, which means your load test results are only as real as the limits you configure.
Close the Debug Loop
The single highest-leverage testing habit: take every failing production call (audio, ASR output, expected intent) and convert it into a deterministic regression test. This prevents the same bug from recurring and rapidly builds a scenario library that reflects your actual caller population, not hypothetical ones.
Gate Your Deploys
Run scenario suites on every pull request. Block releases when voice KPIs cross thresholds: TTFW exceeds 2 seconds at p95, interruption handling drops below your target, or goal completion falls. Hamming’s guide on testing LiveKit voice agents walks through CI examples for exactly this pattern.
The 2026 Short List: Best AI Voice Agent Testing Platforms
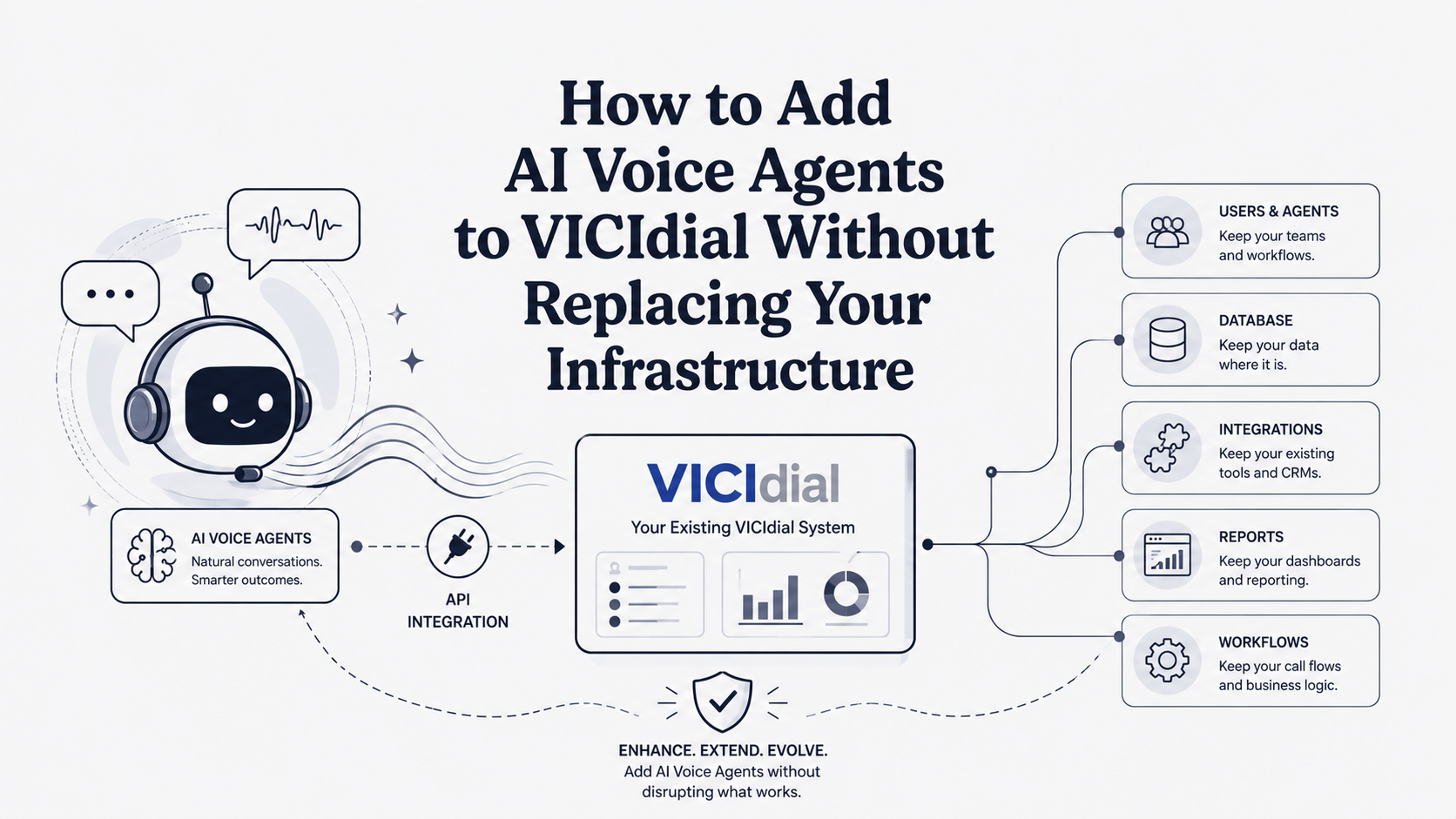
1. SigmaMind AI

Best for: Dev teams and agencies who want to build, test, and deploy voice agents in a single stack, then layer specialized testing tools as volume and risk grow.
Pricing: $0.03/min platform fee plus provider costs for STT, TTS, LLMs, and telephony (pay-as-you-go). Enterprise plans offer custom volume pricing. See the full pricing breakdown.
SigmaMind AI is a YC-backed, developer-first orchestration platform that covers the full lifecycle: build with a no-code agent builder or APIs, test in the built-in Playground with node-level logs, deploy on native US numbers or BYOC via SIP/Twilio/Telnyx, and monitor with layered analytics showing cost breakdowns by stack component.
Key features:
- Model-agnostic across STT (Deepgram), TTS (ElevenLabs, Rime AI, Cartesia), and LLMs (OpenAI, Claude, Gemini, Hume AI), letting you tune cost and quality per layer
- In-builder Playground tests voice, chat, and email workflows with real-time node-level logging before go-live
- APIs and MCP server for wiring agents into CI pipelines from IDEs like VS Code, Copilot, and Cursor
- Warm transfer with structured context headers so human agents receive AI summaries and machine-readable data (no “repeat yourself” moments). Learn more about escalating calls without losing context.
- Sub-second voice-to-voice latency (~970 ms average) and high-concurrency architecture
- App Library with CRM, helpdesk, e-commerce, and calendar integrations so agents complete real tasks (refunds, bookings, order lookups)
- Multi-client workspaces and full-agent import for agencies managing multiple accounts
Tradeoffs:
- International phone numbers require BYO carriers via SIP (direct purchase is US-only)
- True cost per minute spans Platform + STT + TTS + LLM + Telephony, which is transparent but requires tuning across providers
- HIPAA-friendly workflows available, though not HIPAA-compliant/BAA by default (enterprise private cloud options add lead time)
- For teams needing deep red-teaming, 50+ metric observability, or compliance-specific test packs at scale, pairing with a dedicated testing suite (Hamming, Cekura, or Roark) gives the best coverage
Real-world evidence: SigmaMind reports 1M+ calls handled across 1.5k+ live agents. A published case study shows 4,000+ refunds/month automated with 43% cost savings, with turnaround dropping from 2-3 days to under 60 seconds and zero processing errors.
Bottom line: If you want one platform to design multi-node voice workflows, test them in a live playground, deploy on real phone lines, and track per-layer costs, SigmaMind covers the build-test-operate loop. As call volumes grow or regulatory demands increase, plug in specialized voice agent testing platforms from this list for deeper simulation and observability.
Start building and testing for free, or talk to an engineer about enterprise testing workflows.
2. Hamming AI
Best for: Regulated or high-stakes deployments needing audio-native evaluations, HIPAA/SOC 2 compliance, production replay, and large-scale load testing.
Pricing: Contact sales. Enterprise posture with SOC 2 Type II certification and HIPAA BAA available. Community-reported pricing exists on Reddit but is not published by the vendor, so treat any numbers as directional only.
Key features:
- Auto-generated test scenarios from prompts and documentation; production call replay that converts real failures into test cases
- 50+ metrics including turn-taking latency, TTFW, monologue detection, and audio-native sentiment/frustration analysis
- Direct SIP dialing and WebRTC simulation (LiveKit, Pipecat) for testing across both PSTN and browser paths
- CI/CD integration with deploy-gating on voice-specific pass rates
- Claims of 1,000+ calls per minute simulation capacity
Tradeoffs:
- Pricing is completely opaque until you talk to sales
- Likely overkill (and overpriced) for very early-stage teams running fewer than a few hundred calls per day
- Vendor-locked reporting, limited portability of test data
User sentiment: Practitioners on Reddit report switching to Hamming for broader automation at scale, noting better scenario coverage when teams outgrow simpler tools. Community threads position it as a fit for QA teams with enterprise budgets.
3. Cekura

Best for: Teams wanting fast setup, multi-language simulations (30+ languages), and a documented load-testing workflow with explicit concurrency controls.
Pricing: Not publicly listed. Documentation reveals a Developer plan capped at 10 concurrent calls, with higher limits via sales.
Key features:
- No-API-key quickstart with integrations for Retell, Vapi, ElevenLabs, LiveKit, and Pipecat
- Chat-mode testing option that cuts telephony cost and latency for regression runs while still validating conversation logic
- Frequency-based load testing with calls-per-second scheduling; default load metrics for talk ratio, infrastructure issues, and latency
- CI/CD support and production monitoring
Tradeoffs:
- Developer plan concurrency cap (10 calls) limits realistic load testing without upgrading
- Transcript-centric by default; audio-native checks require explicit configuration
- Pricing remains opaque for planning and procurement
User sentiment: Multiple builders on Reddit say Cekura is “easy to get started” and useful because it supports voice scenarios instead of forcing text-only evaluations, a common complaint with general-purpose eval tools.
4. Roark

Best for: Teams that want production call capture, replay against new agent versions, and 40+ built-in metrics with persona and graph-based simulations.
Pricing: Consumption-based with a minimum monthly spend. Exact figures are not published. A third-party comparison from Braintrust’s 2025 roundup cited $500/month for 5,000 minutes, but verify directly with the vendor as this is older data.
Key features:
- 40+ built-in evaluation metrics spanning conversation quality, latency, and goal completion
- Graph-based scenario design and persona simulation
- Multi-speaker analysis supporting up to 15 speakers per call
- 1-click integrations with Vapi, Retell, LiveKit, and Pipecat
- Production monitoring with a loop that turns failing calls into repeatable tests
Tradeoffs:
- Pricing detail requires vendor conversation; minimum spend may not suit very small teams
- Stronger on the production replay loop than on red-teaming or compliance-specific test packs
- Graph-based scenario builder has a learning curve compared to simpler YAML or prompt-based approaches
User sentiment: Entrepreneurs on Reddit discuss using Roark for monitoring and “turning failures into repeatable tests” as the key unlock for improving their voice agents after launch.
5. Coval

Best for: Engineering teams that want CI-triggered regression testing on every commit, auto-generated scenarios from transcripts, and alerting into Slack, Teams, or Linear.
Pricing: Contact sales. Coval also publishes a 2026 Voice AI report with methodology and deployment guidance.
Key features:
- Enterprise-grade regression simulation with an “AV testing”-inspired methodology (think: the rigor applied to self-driving car validation, adapted for voice)
- YC-backed with CI/CD and webhook-driven workflows documented in their developer docs
- Alerting integrations for Slack, Teams, and Linear so failures surface immediately
- Scenario auto-generation from existing transcripts and workflow definitions
Tradeoffs:
- Still early-stage in some vertical-specific test packs
- Quality of results depends heavily on your instrumentation; garbage-in data means garbage-out evaluations
- Pricing opacity makes budget planning difficult for smaller teams
User sentiment: Founders and engineers on Reddit note that “regression runs on every commit helped us stop shipping broken prompts”, highlighting Coval’s value specifically in fast-iteration development cycles.
6. Tuner

Best for: Teams wanting transparent pricing, rapid onboarding, and strong post-production analytics and alerts, with growing pre-production simulation capabilities.
Pricing: As of April 1, 2026: Developers $30/month (~500 calls), Startups $400/month (~10,000 calls), Enterprise custom. Previous free launch access has ended. Published pricing is available on their site.
Key features:
- Observability dashboards with monitoring and evaluation signals
- OpenTelemetry-minded correlation of model behavior and user experience
- Public, transparent pricing tiers (a rarity in this category)
- “Audit” onboarding flow designed for quick time-to-value
Tradeoffs:
- Historically stronger in post-production observability; pre-production simulation is still evolving compared to pure testing vendors
- Fewer integrations with specific voice agent frameworks (LiveKit, Pipecat) compared to Hamming or Cekura
- At the Developer tier, 500 calls/month may not cover serious load-testing needs
User sentiment: A product manager on Reddit shared real PSTN and codec anomalies, underscoring that observability tooling caught what manual testing completely missed. This is a strong argument for pairing production observability with pre-launch testing.
7. Braintrust + Evalion

Best for: Teams standardizing evaluation across voice, text, and multimodal agents, using Evalion for realistic voice caller personas.
Pricing: Braintrust offers a Free tier, Pro at $249+/month, and Enterprise custom. Evalion is contact-sales. Braintrust’s comparative article includes pricing context.
Key features:
- Audio attachments in experiment traces for debugging voice-specific issues
- Custom scorers for latency, goal completion, and domain-specific metrics
- Works with OpenAI’s Realtime API for voice evaluation tasks
- Evalion adds emotional personas and adversarial caller behavior simulation
Tradeoffs:
- Voice simulation quality depends on the Evalion pairing; Braintrust alone doesn’t simulate calls
- Heavier initial setup to achieve full end-to-end voice testing loops compared to purpose-built voice testing platforms
- Custom scorer development requires engineering time upfront
User sentiment: Builders on Reddit compare Braintrust with Langfuse and Maxim, noting Braintrust’s flexibility but acknowledging the wiring effort required. It works well when you need unified evaluations across multiple modalities.
8. VoxTest
Best for: Teams that want YAML-defined voice scenarios, parallelized simulations, and CI blocking without heavy vendor lock-in.
Pricing: Not published. “Get Started Free” language on the site suggests an entry tier.
Key features:
- YAML-based scenario definitions for version-controlled test suites
- Latency and performance charts with transcript analysis
- CLI examples for parallel simulation runs
- CI blocking support to prevent broken agents from shipping
Tradeoffs:
- Younger product with limited public references compared to established platforms
- Feature depth (audio-native evals, production replay) unclear from current documentation
- Small team footprint raises questions about long-term support and roadmap velocity
User sentiment: Early chatter in LiveKit and AI Agents communities on Reddit references VoxTest as an emerging CLI/CI-style tester. Treat as promising but unproven at scale.
9. TestVoice AI

Best for: Agencies and ops teams standardizing voice QA across Vapi, Retell, and Bland agent providers.
Pricing: Free trial/demo available. No public pricing tiers listed.
Key features:
- Concurrent simulations with intent accuracy scoring
- Latency benchmarking across agent providers
- Campaign-style regression runs for batch validation
- Conversation flow validation against expected paths
Tradeoffs:
- Limited public proof points and case studies
- Small-team footprint with unclear roadmap visibility
- Narrower integration surface compared to platforms supporting LiveKit, Pipecat, or custom SIP
User sentiment: Mentioned by developers in LiveKit threads as a tool worth trying for voice agent regression testing. Still early, with limited community feedback.
10. voicetest.dev

Best for: Teams wanting an open-source, code-native AI voice agent testing platform as part of CI with minimal SaaS dependency.
Pricing: Open source. No license fees.
Key features:
- CLI-driven scenario execution with GitHub Actions example YAML
- Environment-based configuration (e.g., GROQ_API_KEY) for flexible provider setup
- Designed for developer-led shops that want full control over test infrastructure
Tradeoffs:
- You must bring your own simulation persona design, audio pipeline instrumentation, and reporting
- No built-in dashboards, alerting, or production replay
- Community support only (no vendor SLA)
User sentiment: Ideal for teams already comfortable building their own tooling. The open-source approach eliminates vendor lock-in but shifts maintenance burden entirely to your team.
11. LiveKit Testing Helpers

Best for: Unit and scenario tests during development for quick iteration on conversation logic. Not a standalone testing platform.
Pricing: Free (part of the LiveKit framework).
Key features:
- Built-in testing utilities for text-mode correctness checks
- Fast feedback loops during development without needing telephony infrastructure
- Well-documented with third-party guides (notably Hamming’s LiveKit testing guide)
Tradeoffs:
- Text-only tests miss timing, jitter, and barge-in behavior entirely
- No PSTN or WebRTC audio simulation
- No production monitoring, load testing, or CI/CD gating
- Must pair with a dedicated voice agent testing platform for anything beyond basic correctness
User sentiment: LiveKit’s own documentation and third-party guides emphasize that text-only tests are a starting point, not a finish line. You need full audio and WebRTC tests before going to production.
Field Guide: Implementing Voice Agent Testing in One Week
Here is a concrete rollout plan for teams going from “we test manually” to “we gate deploys on voice KPIs.”
Days 1-2: Define Scenarios and Wire CI
Start by identifying your top 10 failure modes from production call reviews or customer complaints. Build test scenarios around them: angry callers, interruptions mid-sentence, background noise, accents, silence, and off-topic requests.
If you’re building on SigmaMind AI, use the Playground to run these scenarios with node-level logs and verify each workflow branch. Wire your agent’s API endpoints or MCP server into your CI pipeline so tests run automatically on every pull request.
Days 3-4: Set Up PSTN Test Numbers and Load Shakedown
Provision test phone numbers (US direct or BYOC SIP via Twilio/Telnyx) and run your scenario suite over actual PSTN lines, not just WebRTC. This is where codec, transcoding, and carrier-path issues surface.
For load testing, configure calls-per-second scheduling with realistic call durations. Check your telephony provider’s concurrency caps. A “passing” load test that never actually hit your provider’s limits tells you nothing.
Day 5: Gate Deploys and Build the Replay Loop
Set pass/fail thresholds on your voice KPIs: TTFW under 2 seconds at p95, interruption handling above your target percentage, goal completion above your baseline. Block releases that fail.
Take any production call that fails during the week, extract the audio and ASR output, and convert it into a regression test case. This single habit will compound quickly.
For teams exploring the full SigmaMind platform architecture (APIs, BYOC SIP, omnichannel support), this week gets you from zero to automated voice testing with minimal vendor sprawl. As volumes grow, layer in specialized testing or observability from the platforms above.
Frequently Asked Questions
Can we get away with text-only testing for voice agents?
No. Text-only tests validate conversation logic but miss everything that makes voice different: latency, barge-in handling, audio artifacts, codec issues, and PSTN-specific failures. Use text-mode tests for fast iteration during development, then run full audio and PSTN tests before any production deployment.
What is a reasonable TTFW (time-to-first-word) target?
Start with under 2 seconds at p95, based on Hamming’s testing framework guidance. Premium customer experience use cases (healthcare, financial services) may warrant stricter targets. Track the full distribution, not just the average.
Why does PSTN testing matter if our demo works fine on WebRTC?
WebRTC bypasses carrier routing, codec transcoding, and DTMF handling. Production callers dial from mobile phones and landlines over PSTN, introducing latency, jitter, and audio quality degradation that never appears in browser-based tests. Teams on Reddit consistently report that demos hide real-world PSTN quirks that cause failures in production.
How many concurrent test calls do I need for realistic load testing?
Match your expected peak production concurrency, then add 20-30% headroom. More importantly, sustain calls at production-length durations (2-5 minutes for typical use cases) rather than running short bursts. Check your telephony provider’s concurrency caps, as many plans have limits that can produce false “pass” results if your test never exceeds them.
Should I build testing in-house or buy a platform?
For basic smoke tests and CI checks, open-source tools like voicetest.dev work. For simulation realism (accents, emotional personas, background noise), audio-native metrics (50+ signals), production replay, and scale beyond a few hundred daily calls, a dedicated AI voice agent testing platform pays for itself in bugs caught before they reach callers. Most teams use a combination: an orchestration platform like SigmaMind AI for build-test-deploy, paired with a specialized testing suite for depth.
What hidden costs should I watch for in voice agent testing platform pricing?
Nearly every vendor charges for telephony minutes, STT/TTS inference, and LLM usage on top of their platform fee. A $30/month plan that requires 10,000 test calls quickly becomes expensive when you add per-minute telephony and inference costs. Ask vendors for a fully loaded cost-per-test-call estimate, not just the platform subscription.
How do I convert production failures into regression tests?
Capture the failing call’s audio recording, ASR transcript, expected intent or goal, and the actual agent response. Feed these into your testing platform as a deterministic scenario with a known-correct expected outcome. Run this scenario on every subsequent deploy. Over time, your regression suite becomes a living record of every bug your agent has encountered and fixed.
Can one platform handle both building voice agents and testing them?
Yes, though with tradeoffs. Platforms like SigmaMind AI cover the build-test-deploy loop with integrated playground testing, APIs for CI, and analytics. For teams with high call volumes, regulated industries, or complex red-teaming needs, pairing the build platform with a specialized testing vendor (Hamming for compliance, Cekura for multi-language simulation, Roark for production replay) gives the strongest coverage.